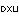My Type of Language

I have no formal training in type theory – I don’t have much informal training – I’m still lost when I crack open Benjamin Pierce’s Types and Programming Languages book. I do, however, have smart co-maintainers and a lot of experience banging my head against this small DSL called bpftrace.
As you probably know, bpftrace, the language, is an abstraction of BPF C code, which is itself a restricted version of standard C that runs in the Linux kernel. One of the “value adds” of bpftrace is that users don’t need explicit types. bpftrace is statically typed but the types are inferred. So, in the statement $x = 5, $x is resolved to an signed 8-bit integer. For the most part, this was a good language design choice as bpftrace’s goals are to be fast, terse, and flexible. However, this choice has had its issues; both externally in terms of causing strange user errors and internally with how the type system was built.
This post is about bpftrace’s type system and how it’s improved over the past 2 years.