The Path to 1.0


If you have used bpftrace you know how useful it can be for debugging complex issues. There are many bpftrace scripts that yield tons of valuable information about your system in just one line of code. Historically, bpftrace has focused on powerful, terse, but narrowly scoped, features to solve specific problems but as these features multiplied, so did the complexity and the inability to compose them together.
Users who wanted to write larger scripts found bpftrace missing basic capabilities that are common in programming languages, e.g., functions to factor common code, an ability to declare variables or control types and sizes, basic loop control flow, etc. Furthermore, functionality not exposed by a specific bpftrace builtin required changes to bpftrace itself; this meant touching multiple parts of the core codebase. It also meant adding LLVM IR code, which is similar to writing assembly but with added BPF verifier constraints and support for multiple LLVM versions (painful and often a non-starter for new contributors). If that wasn’t enough, users would then have to wait for a new bpftrace release, which only happens a few times a year. This then had the additional downstream effect of bpftrace falling behind upstream BPF capabilities.
A telling data point is the footprint that bpftrace has on the internet. While examples of small scripts are common, very few large scripts can be found. Only 10k lines worth of unique scripts are readily found on GitHub (many within the bpftrace org repos), averaging only 50 lines each. Meanwhile, the bpftrace code itself is over 50k lines - 5x! It's rare for a language implementation to vastly outsize all the artifacts created in that language.
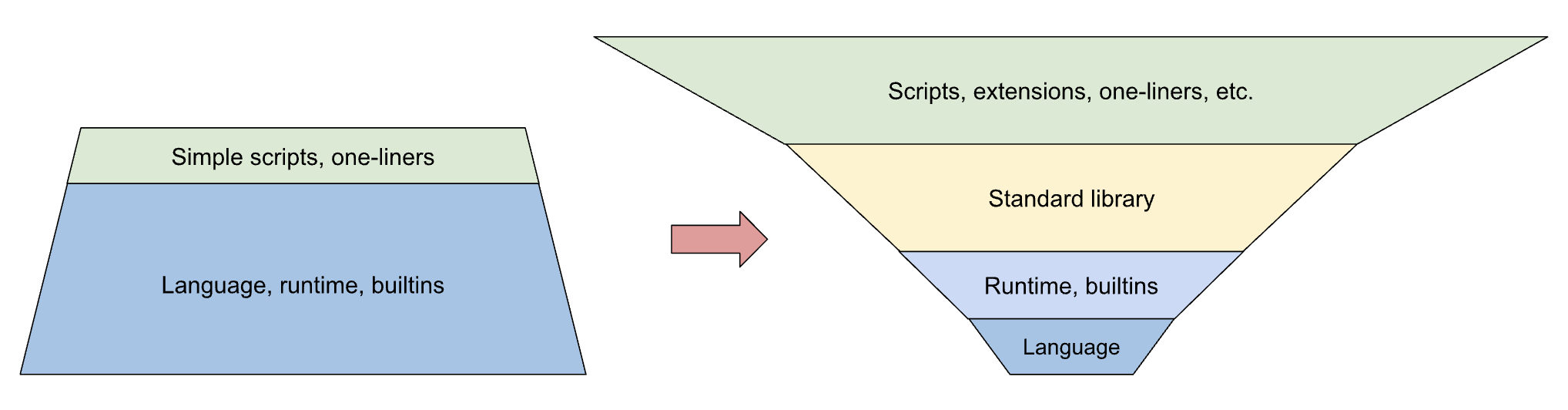
A lot has been accomplished and one-liners are great but we want users to be able to build large, complex observability programs with bpftrace. This means new primitives should work seamlessly with existing ones, there exists a robust standard library, clear documentation, a stable type system, and an ability to extend the functionality of bpftrace without needing to make changes to the core code. bpftrace should remain easy to understand, fast, accurate, and reliable. In essence, we want a foundation that will carry us far into the future; one that we can proudly label 1.0.
This series of posts details some of the interesting and powerful new capabilities we've added (and are still adding) on this journey to 1.0: